Bài viết này dựa trên ghi chép cho bài thuyết trình tôi đã trình bày tại EAG Boston 2017. Bạn có thể xem bản ghi âm tại đây.
Nguy cơ đau khổ quy mô vũ trụ (suffering risks hay viết tắt s-risks) là những sự kiện rủi ro gây đau khổ mức độ “đáng kể” tầm vũ trụ. Khi nói "đáng kể", chúng tôi ám chỉ đáng kể trong tương quan với lượng đau khổ dự kiến trong tương lai. Bài thuyết trình này dành cho đối tượng mới làm quen với khái niệm này. Để thảo luận sâu hơn, hãy xem bài viết của chúng tôi Giảm thiểu rủi ro đau khổ vũ trụ: Một vấn đề đáng ưu tiên song thiếu sự quan tâm.
Tôi sẽ nói về những rủi ro gây ra đau khổ nghiêm trọng trong tương lai xa, hay còn gọi là s-risks, nguy cơ đau khổ quy mô vũ trụ. Giảm thiểu những rủi ro này là trọng tâm chính của Viện Nghiên cứu Cơ bản (Foundational Research Institute), nhóm nghiên cứu EA mà tôi đại diện.
Để minh họa cho khái niệm nguy cơ đau khổ quy mô vũ trụ (s-risks) , tôi sẽ sử dụng một câu chuyện hư cấu.

Hãy tưởng tượng rằng: một ngày nào đó, con người có thể tải trí óc của mình vào các môi trường ảo. Nhờ đó, các thực thể có ý thức có thể được lưu trữ và vận hành trên các thiết bị tính toán cực kỳ nhỏ gọn, như thiết bị hình trứng màu trắng được mô tả ở đây.

Bạn có thể thấy Matt phía sau thiết bị điện toán. Công việc của Matt là thuyết phục các bản sao kỹ thuật số của con người (human uploads) trở thành những người hầu ảo, điều khiển nhà thông minh cho chủ nhân của họ. Trong trường hợp này thì Greta - một bản sao kỹ thuật số của người, lại từ chối tuân theo.

Để làm suy yếu ý chí Greta, Matt tăng tốc độ thời gian trôi qua cô. Trong khi Matt chỉ chờ đợi vài giây, Greta thực sự phải chịu đựng nhiều tháng bị giam cầm một mình.
May mắn điều này không thực sự xảy ra. Thực tế là tôi đã lấy câu chuyện và các hình ảnh từ một tập trong series truyền hình Anh - Black Mirror.
Cảnh tượng trên không xảy ra trong thực tế, và chắc chắn sẽ không bao giờ xảy ra trong thế giới ảo. Không có kịch bản tương lai nào mà chúng ta đang tưởng tượng hiện nay lại có khả năng xảy ra chính xác theo cách này.

Nhưng, tôi sẽ lập luận rằng: có những kịch bản khả thi khác có nhiều điểm tương đồng quan trọng, thậm chí còn tồi tệ hơn kịch bản phim trên. Tôi sẽ gọi những kịch bản này là "nguy cơ đau khổ quy mô vũ trụ", trong đó "s" đại diện cho "sự đau khổ" - “suffering”.
Tôi sẽ giải thích chi tiết về nguy cơ đau khổ quy mô vũ trụ là gì và cách nguy cơ đau khổ quy mô vũ trụ có thể xảy ra. Tiếp theo, tôi sẽ thảo luận về lý do tại sao những người theo chủ nghĩa vị tha/ thiện nguyện hiệu quả có thể muốn tập trung vào việc ngăn chặn nguy cơ đau khổ quy mô vũ trụ, và thông qua những loại công việc nào để có thể làm được điều đó.

Tôi muốn giới thiệu “nguy cơ đau khổ quy mô vũ trụ” như một phân loại thuộc rủi ro hiện sinh, thường được gọi là x-risk (existential risk). Do đó, sẽ hữu ích nếu chúng ta ôn lại khái niệm về x-risk. Nick Bostrom đã định nghĩa x-risk như sau.
“Rủi ro hiện sinh là loại rủi ro mà kết quả tiêu cực sẽ tiêu diệt hoàn toàn sự sống thông minh khởi sinh từ Trái Đất, hoặc hạn chế nghiêm trọng và lâu dài tiềm năng của chúng.”
Bostrom cũng đề xuất cách hiểu sự khác biệt giữa x-risk và các loại rủi ro khác. Đó là xem xét hai chiều của rủi ro. Hai chiều này là: quy mô (scope) và mức độ nghiêm trọng (severity).
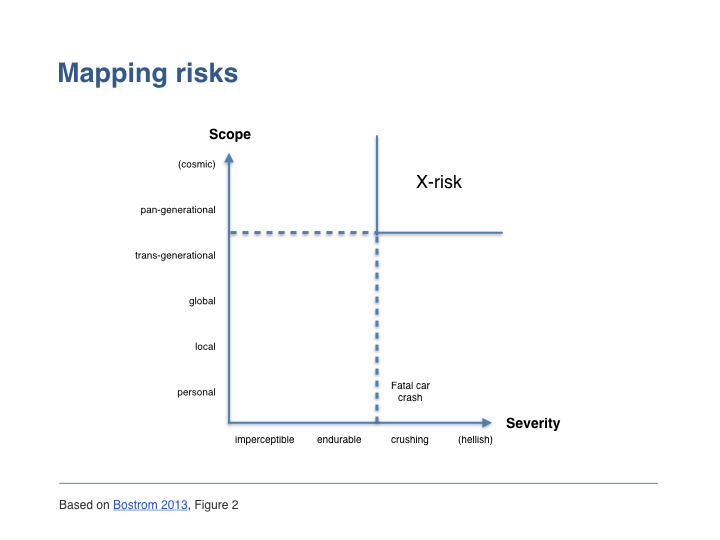
Chúng ta có thể sử dụng các yếu tố này để phân loại rủi ro trên một hình vẽ hai chiều. Trên trục dọc, rủi ro được sắp xếp theo phạm vi ảnh hưởng. Tức là, chúng ta hỏi có bao nhiêu cá nhân sẽ bị ảnh hưởng? Chỉ một người, tất cả mọi người ở một địa phương, tất cả mọi người trên Trái Đất tại một thời điểm, hay thậm chí tất cả mọi người hiện tại cộng thêm các thế hệ tương lai? Trên trục ngang, chúng ta phân loại rủi ro theo mức độ nghiêm trọng. Tức là, chúng ta hỏi: hậu quả tiêu cực ảnh hưởng nghiêm trọng đến mức nào tới mỗi cá nhân.
Ví dụ, một vụ tai nạn xe hơi chết người có mức độ nghiêm trọng cực độ. Theo nghĩa là nó rất tồi tệ. Nhưng khi xem xét khác đi, nó mới ở phạm vi cá nhân và nó còn có thể tồi tệ hơn vì chỉ ảnh hưởng đến một số ít người, chứ không phải toàn cầu hay thậm chí quy mô khu vực. Nhưng cũng có những rủi ro có mức độ nghiêm trọng cao hơn; ví dụ, bị tra tấn suốt đời mà không có cơ hội thoát thân, có thể tồi tệ hơn một vụ tai nạn xe hơi gây tử vong. Hoặc một ví dụ thực tế là chăn nuôi công nghiệp. Ví dụ, chúng ta thường cho rằng: cuộc đời của gà nuôi nhốt trong lồng chật chội là quá tồi tệ đến mức tốt hơn là không nên để gà sống như thế ngay từ đầu. Đó là lý do tại sao chúng tôi cho rằng việc thực phẩm tại hội nghị này chủ yếu là chay là điều tốt.
Để quay lại tiêu đề bài phát biểu của tôi, tôi có thể giải thích tại sao nguy cơ đau khổ quy mô vũ trụ là những rủi ro hiện sinh tồi tệ nhất. Nguy cơ đau khổ quy mô vũ trụ là những rủi ro hiện sinh tồi tệ nhất vì tôi sẽ định nghĩa chúng có phạm vi lớn nhất có thể và mức độ nghiêm trọng lớn nhất có thể. (Tôi sẽ làm rõ khẳng định rằng nguy cơ đau khổ quy mô vũ trụ là những rủi ro x-risks tồi tệ nhất sau này.) Đó là, tôi đề xuất định nghĩa sau:
“Nguy cơ đau khổ quy mô vũ trụ – Một nguy cơ mà kết quả tiêu cực sẽ gây ra đau khổ nghiêm trọng trên quy mô vũ trụ, vượt xa tất cả đau khổ đã tồn tại trên Trái Đất cho đến nay.”
Vậy, nguy cơ đau khổ quy mô vũ trụ có mức độ nghiêm trọng tương đương với chăn nuôi công nghiệp, nhưng với phạm vi mở rộng quy mô.
Để hiểu rõ hơn định nghĩa này, hãy tập trung vào bản đồ thể hiện rủi ro hiện sinh.
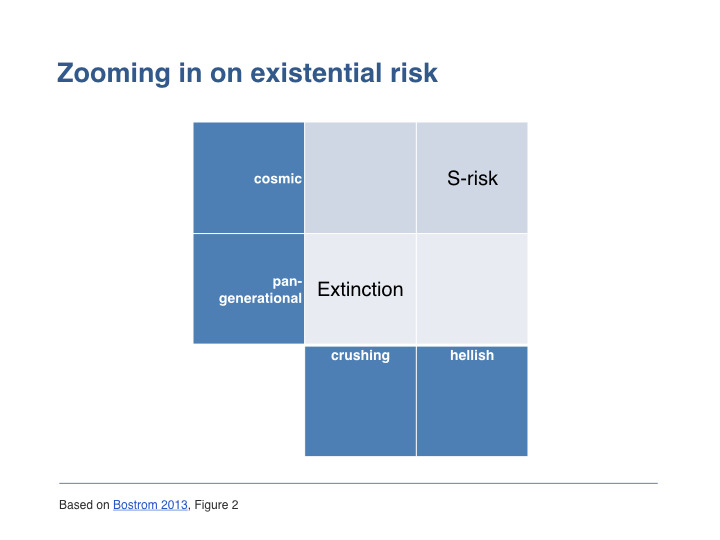
Một phân loại rủi ro là những rủi ro có phạm vi ảnh hưởng đến tất cả các thế hệ con người trong tương lai và có mức độ nghiêm trọng đến mức có thể tiêu diệt mọi giá trị. Một ví dụ điển hình về loại rủi ro toàn thế hệ (pan-generational), có sức tàn phá khủng khiếp này là rủi ro tuyệt chủng loài người.
Rủi ro tuyệt chủng đã nhận được sự quan tâm nhiều nhất cho đến nay. Tuy nhiên, về mặt khái niệm, các rủi ro x-risks còn bao gồm một loại rủi ro khác. Đây là những rủi ro có kết quả thậm chí tồi tệ hơn cả sự tuyệt chủng ở hai khía cạnh. Thứ nhất, về phạm vi, chúng không chỉ đe dọa các thế hệ tương lai của con người hoặc hậu duệ của chúng ta, mà còn đe dọa tất cả sự sống có ý thức trong toàn vũ trụ. Thứ hai, về mức độ nghiêm trọng, chúng không chỉ loại bỏ mọi thứ có giá trị mà còn kèm theo rất nhiều giá trị tiêu cực – tức là những đặc điểm mà chúng ta muốn tránh bằng mọi giá. Hãy nhớ lại câu chuyện tôi đã kể ở đầu, nhưng hãy tưởng tượng việc Greta bị giam giữ một mình được nhân lên hàng nghìn lần – ví dụ, vì nó ảnh hưởng đến một số lượng lớn các bản sao có ý thức.

Hãy dừng lại một chút. Đến nay, tôi đã giới thiệu khái niệm về rủi ro đau khổ (s - risks). Tóm lại, đó là những rủi ro gây ra đau khổ nghiêm trọng trên quy mô vũ trụ, khiến chúng trở thành một tập hợp con của rủi ro hiện sinh (existential risk hay x - risk).
(Tùy thuộc vào cách bạn hiểu trường hợp "hạn chế tiềm năng" trong định nghĩa về x-risks, thực tế có thể có những s-risks không phải là x-risks. Điều này sẽ đúng nếu bạn cho rằng việc đạt được tiềm năng đầy đủ của cuộc sống thông minh có nguồn gốc từ Trái Đất có thể liên quan đến đau khổ trên quy mô thiên văn (astronomical scale), tức là sự hiện thực hóa một s-risk. Hãy tưởng tượng một phần tư vũ trụ chứa đựng đau khổ, và ba phần tư còn lại chứa đựng hạnh phúc. Xem xét kết quả này là tiềm năng đầy đủ của nhân loại dường như yêu cầu quan điểm rằng: đau khổ liên quan sẽ bị lấn át bởi các đặc điểm mong muốn khác của việc đạt được tiềm năng đầy đủ này, chẳng hạn như lượng hạnh phúc khổng lồ. Mặc dù tất cả các quan điểm đạo đức có thể chấp nhận được dường như đều đồng ý rằng ngăn chặn đau khổ trong kịch bản này là có giá trị, họ có thể không đồng ý về mức độ quan trọng của việc làm đó. Mặc dù nhiều người cho rằng đảm bảo một tương lai thịnh vượng là quan trọng hơn, FRI cam kết với một nhóm quan điểm khác nhau, mà chúng tôi gọi là đạo đức tập trung vào đau khổ. (Lưu ý: Chúng tôi đã cập nhật phần này vào tháng 6 năm 2019.))
Tiếp theo, tôi muốn nói về lý do và cách ngăn chặn các rủi ro đau khổ s-risk.
Tất cả các hệ thống giá trị hợp lý đều đồng ý rằng đau khổ, trong điều kiện khác như nhau, là điều không mong muốn. Tức là, mọi người đều đồng ý rằng chúng ta có lý do để tránh đau khổ. S-risks là những rủi ro gây ra đau khổ lớn, vì vậy tôi hy vọng bạn đồng ý rằng việc ngăn chặn s-risks là điều tốt.
Tuy nhiên, bạn có thể ở đây vì bạn quan tâm đến chủ nghĩa vị tha hiệu quả/ thiện nguyện hiệu quả (Effective altruism). Bạn không muốn biết liệu việc ngăn chặn rủi ro đau khổ s - risk có phải là điều tốt hay không, vì có rất nhiều điều tốt khác bạn có thể làm. Bạn thừa nhận rằng làm điều tốt có chi phí cơ hội, vì vậy bạn đang tìm kiếm điều tốt nhất có thể để làm. Liệu việc ngăn chặn rủi ro đau khổ s -risk có thể đáp ứng tiêu chuẩn cao hơn này một cách hợp lý?

Đây là một câu hỏi rất phức tạp. Để hiểu rõ mức độ phức tạp của nó, trước tiên tôi muốn giới thiệu một lập luận sai lầm về việc tập trung vào việc giảm thiểu rủi ro đau khổ (s-risk). (Tôi không khẳng định rằng ai đó đã đưa ra lập luận như vậy về cả rủi ro s-risk lẫn rủi ro hiện sinh x-risk.) Lập luận sai lầm này như sau.

Đề xuất 1: Điều tốt nhất nên làm là ngăn chặn những rủi ro tồi tệ nhất
Đề xuất 2: Rủi ro đau khổ S-risk là những rủi ro tồi tệ nhất
Kết luận: Điều tốt nhất nên làm là ngăn chặn rủi ro đau khổ S-risk
Tôi đã nói rằng lập luận này không hợp lý. Tại sao?
Trước khi đi sâu vào vấn đề này, hãy loại bỏ một nguồn gây nhầm lẫn tiềm ẩn. Theo một cách hiểu, tiền đề 1 có thể là một phán đoán giá trị. Trong ý nghĩa này, nó có thể có nghĩa là, bất kể bạn mong đợi điều gì sẽ xảy ra trong tương lai, bạn cho rằng có một lý do cụ thể để ưu tiên ngăn chặn những kết quả tồi tệ nhất. Có rất nhiều điều có thể nói về ưu nhược điểm cũng như những hệ quả của quan điểm này, nhưng đây không phải là ý nghĩa của tiền đề 1 mà tôi sẽ đề cập. Dù sao đi nữa, tôi không nghĩ rằng bất kỳ cách hiểu nào dựa hoàn toàn vào giá trị của tiền đề 1 là đủ để xây dựng lập luận này. Nói chung, tôi tin rằng giá trị của bạn có thể cung cấp những lý do đáng kể hoặc thậm chí quyết định để tập trung vào rủi ro đau khổ s-risk, nhưng tôi sẽ dừng lại ở đó.
Điều tôi muốn tập trung thay vào, đó là (gần như) bất kể giá trị của bạn là gì, tiền đề 1 là sai. Hoặc ít nhất nó sai nếu, bằng "những rủi ro tồi tệ nhất", chúng ta hiểu những gì chúng ta đã thảo luận cho đến lúc này, tức là mức độ tồi tệ theo cả chiều kích phạm vi lẫn mức độ nghiêm trọng.

Khi cố gắng xác định hành động có tác động đạo đức lớn nhất, tất nhiên có những tiêu chí quan trọng hơn phạm vi và mức độ nghiêm trọng của rủi ro. Những gì còn thiếu là xác suất của rủi ro; khả năng phòng ngừa nó; và mức độ bị bỏ qua của nó. S-risks, theo định nghĩa, là những rủi ro tồi tệ nhất về phạm vi và mức độ nghiêm trọng, nhưng không nhất thiết là về xác suất, khả năng phòng ngừa và mức độ bị bỏ qua.
Những tiêu chí bổ sung này rõ ràng là có liên quan. Ví dụ, nếu rủi ro S-risk có xác suất bằng không, hoặc việc giảm thiểu chúng hoàn toàn không thể thực hiện được, thì việc cố gắng giảm thiểu chúng sẽ không có ý nghĩa.
Chúng ta do đó phải loại bỏ lập luận sai lầm này. Tôi không thể trả lời một cách dứt khoát câu hỏi về hoàn cảnh nào chúng ta nên tập trung vào rủi ro đau khổ (s-risk), nhưng tôi sẽ đưa ra một số suy nghĩ ban đầu về xác suất, khả năng kiểm soát và mức độ bị bỏ qua của chúng.

Tôi sẽ lập luận rằng rủi ro s-risks không hề ít khả năng xảy ra hơn so với rủi ro tuyệt chủng liên quan đến trí tuệ nhân tạo (AI). Tôi sẽ giải thích tại sao tôi cho rằng điều này là đúng và sẽ giải quyết hai phản biện trong quá trình đó.
Bạn có thể nghĩ “điều này thật ngớ ngẩn”, chúng ta thậm chí còn không thể đưa con người lên sao Hỏa, tại sao lại lo lắng về nỗi đau trên quy mô vũ trụ? Đây chắc chắn là phản ứng trực giác ban đầu của tôi khi lần đầu tiếp xúc với các khái niệm liên quan. Nhưng với tư cách là những người theo chủ nghĩa vị tha hiệu quả/ thiện nguyện hiệu quả (Effective altruism - EAs), chúng ta nên thận trọng khi đánh giá các phản ứng trực giác, ‘hệ thống 1’, từ bề ngoài. Bởi vì chúng ta biết rằng một lượng lớn nghiên cứu tâm lý học theo tiếp cận “các quy tắc phỏng đoán và sai lệch nhận thức” (“heuristics and biases”) cho thấy ước tính xác suất trực giác của chúng ta thường bị ảnh hưởng bởi mức độ dễ dàng mà chúng ta có thể nhớ lại một ví dụ điển hình của sự kiện đang xem xét. Đối với các loại sự kiện không có tiền lệ trong lịch sử, chúng ta không thể nhớ lại bất kỳ ví dụ điển hình nào, và do đó chúng ta đang đánh giá thấp một cách hệ thống xác suất của các sự kiện đó nếu không cẩn thận.
Vì vậy, chúng ta nên xem xét một cách phê phán phản ứng trực giác cho rằng các rủi ro cấp độ s-risk là không khả thi. Nếu làm điều này, chúng ta nên chú ý đến hai phát triển công nghệ, ít nhất là có thể xảy ra và mà chúng ta có lý do để mong đợi vì những lý do không liên quan. Đó là trí tuệ nhân tạo có ý thức và trí tuệ nhân tạo siêu thông minh, loại sau mở ra nhiều khả năng công nghệ hơn như định cư không gian.
Trí tuệ nhân tạo có khả năng trải nghiệm chủ quan đề cập đến ý tưởng rằng khả năng có trải nghiệm chủ quan, và đặc biệt là khả năng chịu đựng đau khổ, không chỉ giới hạn ở động vật sinh học. Mặc dù không có sự đồng thuận phổ quát về điều này, nhưng hầu hết các quan điểm đương đại trong triết học tâm trí đều ngụ ý rằng trí tuệ nhân tạo có khả năng trải nghiệm chủ quan là có thể về mặt nguyên tắc. Đối với trường hợp cụ thể của mô phỏng não bộ, các nhà nghiên cứu đã vạch ra một lộ trình cụ thể, xác định các mốc quan trọng và những điểm không chắc chắn còn lại.
Về trí tuệ nhân tạo siêu thông minh, tôi sẽ không nói thêm về điều này vì đây là công nghệ đã nhận được nhiều sự chú ý từ cộng đồng EA. Tôi chỉ đề cập đến cuốn sách xuất sắc của Nick Bostrom về chủ đề này, có tựa đề Superintelligence (Siêu trí tuệ - đã dịch ra tiếng Việt), và thêm rằng các rủi ro liên quan đến trí tuệ nhân tạo có ý thức và "trí tuệ nhân tạo đi sai hướng" đã được Bostrom thảo luận dưới thuật ngữ "tội ác tâm trí".
Nhưng nếu bạn chỉ nhớ một điều về xác suất của rủi ro siêu trí tuệ, hãy nhớ điều này: Đây không phải là "đánh cược kiểu Pascal"! Kể ngắn gọn thì, như bạn có thể nhớ, Pascal sống vào thế kỷ 17 và đặt câu hỏi liệu chúng ta có nên tuân theo các mệnh lệnh tôn giáo hay không. Một trong những lập luận ông xem xét là, dù chúng ta cho rằng khả năng Chúa tồn tại là rất thấp, thì cũng không đáng để mạo hiểm rơi vào địa ngục. Nói cách khác, địa ngục quá tồi tệ đến mức bạn nên ưu tiên tránh nó, ngay cả khi bạn cho rằng có rất ít khả năng địa ngục tồn tại
Nhưng đó không phải là lập luận chúng ta đưa ra về rủi ro đau khổ (s-risk). “Đánh cược kiểu Pascal” dựa trên một suy đoán dựa trên một bộ sưu tập sách cổ xưa được chọn ngẫu nhiên. Dựa trên điều này, không thể khẳng định một cách hợp lý rằng xác suất của một loại địa ngục nào đó cao hơn xác suất của các giả thuyết cạnh tranh.
Ngược lại, lo ngại về rủi ro s-risk dựa trên các lý thuyết khoa học tốt nhất của chúng ta và rất nhiều kiến thức thực nghiệm ngầm về thế giới. Chúng ta xem xét tất cả bằng chứng có sẵn, sau đó xác định một phân phối xác suất về cách tương lai có thể diễn ra. Vì dự đoán tương lai rất khó khăn, sự không chắc chắn còn lại sẽ rất cao. Nhưng loại lập luận này về nguyên tắc có thể biện minh cho kết luận rằng rủi ro s-risk không phải là nhỏ đến mức có thể bỏ qua.
OK, nhưng có thể bạn nghĩ đến một lập luận bổ sung: vì một vũ trụ đầy rẫy đau khổ là một kết quả tương đối cụ thể, bạn có thể cho rằng điều này cực kỳ khó xảy ra trừ khi có ai đó hoặc thứ gì đó cố ý tối ưu hóa cho kết quả đó. Nói cách khác, bạn có thể cho rằng rủi ro đau khổ s-risk đòi hỏi ý định xấu, và ý định xấu như vậy là rất hiếm.

Tôi cho rằng một phần của lập luận này là đúng: Tôi đồng ý rằng khả năng chúng ta tạo ra một trí tuệ nhân tạo (AI) với mục tiêu cuối cùng là gây ra đau khổ, hoặc con người sẽ cố ý tạo ra một số lượng lớn AI gây đau khổ, là rất thấp. Nhưng tôi cho rằng ý đồ xấu chỉ chiếm một phần rất nhỏ trong những điều chúng ta nên lo lắng, vì còn hai con đường khác, khả thi hơn.
Ví dụ, hãy xem xét khả năng rằng những thực thể trí tuệ nhân tạo đầu tiên mà chúng ta tạo ra, có thể với số lượng rất lớn, có thể "không có tiếng nói" (voiceless), không thể giao tiếp bằng ngôn ngữ viết. Nếu chúng ta không cẩn thận, chúng ta có thể gây ra đau khổ cho chúng mà thậm chí không nhận ra.
Tiếp theo, hãy xem xét câu chuyện điển hình về rủi ro AI: một hệ thống siêu thông minh tối ưu hóa kẹp giấy. Một lần nữa, điểm mấu chốt không phải là ai đó cho rằng kịch bản cụ thể này rất có khả năng xảy ra. Đó chỉ là một ví dụ về một lớp kịch bản rộng lớn, trong đó chúng ta vô tình tạo ra một hệ thống tương tự như tác nhân có sức mạnh, theo đuổi một mục tiêu không phù hợp với giá trị của chúng ta cũng không phải là ác ý. Điểm mấu chốt là hệ thống tối ưu hóa kẹp giấy này vẫn có thể gây ra đau khổ vì lý do mang tính công cụ (instrumental reasons). Ví dụ, nó có thể chạy các mô phỏng có ý thức để tìm hiểu thêm về khoa học sản xuất kẹp giấy, hoặc để đánh giá khả năng gặp phải người ngoài hành tinh (có thể làm gián đoạn sản xuất kẹp giấy); hoặc nó có thể tạo ra các chương trình con có ý thức "công nhân" mà đau khổ đóng vai trò hướng dẫn hành động tương tự cách con người học không chạm vào bếp nóng.
Một thế hệ AI có ý thức "đầu tiên và không có tiếng nói" và tối ưu hóa kẹp giấy gây ra đau khổ vì lý do mang tính công cụ là hai ví dụ về cách một rủi ro đau khổ (s-risk) có thể xảy ra, không phải do ý định xấu xa, mà do tai nạn.
Thứ ba, rủi ro s-risk có thể nảy sinh như một phần của xung đột.
Để hiểu ý nghĩa của điểm thứ ba, hãy nhớ lại câu chuyện từ đầu bài nói chuyện này. Người điều khiển con người Matt không phải là ác độc theo nghĩa anh ta coi trọng sự đau khổ của Greta. Anh ta chỉ muốn đảm bảo rằng Greta tuân thủ các lệnh của chủ nhân, bất kể chúng là gì. Một cách tổng quát hơn, nếu các tác nhân cạnh tranh cho một nguồn tài nguyên chung, có nguy cơ họ sẽ tham gia vào hành vi chiến lược có tổng âm gây ra đau khổ, ngay cả khi mọi người đều coi thường đau khổ.
Kết quả là, rủi ro về đau khổ nghiêm trọng không yêu cầu những động cơ hiếm hoi như bạo lực hay thù hận. Có rất nhiều bằng chứng thực tế cho nguyên tắc đáng lo ngại này trong lịch sử; ví dụ, hãy nhìn vào hầu hết các cuộc chiến tranh hoặc chăn nuôi công nghiệp. Cả hai đều không phải do ý định xấu xa gây ra.
Thêm vào đó, nếu bạn thắc mắc, câu chuyện Black Mirror không phải là rủi ro s-risk, nhưng bây giờ chúng ta có thể thấy nó minh họa hai điểm chính: đầu tiên, tầm quan trọng của trí tuệ nhân tạo có ý thức, và thứ hai, đau khổ nghiêm trọng do một tác nhân không có ý định xấu gây ra.
Kết luận: Để lo lắng về rủi ro đau khổ s-risk, chúng ta không cần giả định bất kỳ công nghệ mới nào hoặc bất kỳ đặc điểm mới nào vượt quá những gì đã được cộng đồng rủi ro AI xem xét. Vì vậy, tôi cho rằng rủi ro đau khổ (s-risk) không kém phần khả năng xảy ra so với rủi ro hiện sinh (x-risk) liên quan đến AI. Hoặc ít nhất, nếu ai đó lo lắng về rủi ro hiện sinh (x-risk) liên quan đến AI nhưng không lo lắng về rủi ro đau khổ (s-risk), thì trách nhiệm chứng minh thuộc về họ.

Tôi thừa nhận đây là một câu hỏi đầy thách thức. Tuy nhiên, tôi cho rằng vẫn có một số việc chúng ta có thể làm ngay hôm nay để giảm thiểu rủi ro đau khổ (s-risk).
Đầu tiên, có một số điểm trùng lặp với các công việc quen thuộc trong lĩnh vực rủi ro hiện sinh (x-risk). Cụ thể hơn, một số công việc trong lĩnh vực an toàn AI kỹ thuật và chính sách AI đang giải quyết hiệu quả cả hai loại rủi ro: rủi ro tuyệt chủng (extinction risk)và rủi ro đau khổ s-risk. Tuy nhiên, bất kỳ công việc cụ thể nào trong lĩnh vực an toàn AI có thể phù hợp hơn với một loại rủi ro so với loại còn lại. Để đưa ra một ví dụ đơn giản, nếu chúng ta có thể đảm bảo rằng một AI siêu thông minh sẽ tự động tắt sau 1000 năm, điều này sẽ không giúp giảm thiểu rủi ro tuyệt chủng nhưng sẽ ngăn chặn rủi ro đau khổ s-risk kéo dài. Đối với những suy nghĩ nghiêm túc hơn về tiến bộ khác biệt trong an toàn AI, tôi đề nghị bạn tham khảo báo cáo kỹ thuật của Viện Nghiên cứu Cơ bản về Suffering-focused AI Safety.
Tin tốt là chúng ta đã đang thực hiện các công việc giảm thiểu rủi ro khổ đau s-risk. Tuy nhiên, điều này không áp dụng cho tất cả các công việc về rủi ro hiện sinh (existential risk, x - risk); ví dụ, xây dựng các khu trú ẩn thảm họa hoặc làm giảm khả năng chúng ta bị tiêu diệt bởi một đại dịch chết người có thể giảm xác suất tuyệt chủng — nhưng, về cơ bản, nó không thay đổi quỹ đạo tương lai nếu con người còn tồn tại.
Bên cạnh các công việc tập trung hơn, còn có các can thiệp rộng hơn có thể ngăn chặn rủi ro tồn vong một cách gián tiếp. Ví dụ, tăng cường hợp tác quốc tế có thể giảm khả năng xảy ra xung đột, và chúng ta đã thấy rằng hành vi tiêu cực trong xung đột là một nguồn tiềm năng của rủi ro tồn vong. Hoặc, ở mức độ cao hơn, chúng ta có thể tiến hành nghiên cứu nhằm xác định chính xác loại can thiệp rộng nào hiệu quả trong việc giảm rủi ro tồn vong. Phần sau là một phần của những gì chúng tôi đang làm tại Foundational Research Institute.
Tôi đã đề cập đến việc liệu có các can thiệp giảm thiểu rủi ro đau khổ (s-risk) hay không. Có một khía cạnh khác của tính khả thi: liệu có đủ sự ủng hộ để thực hiện các can thiệp đó hay không? Ví dụ, liệu có đủ kinh phí hay không? Chúng ta có thể lo lắng rằng việc đề cập đến nỗi đau cấp vũ trụ (cosmic suffering) và trí tuệ nhân tạo có ý thức nằm ngoài phạm vi thảo luận chấp nhận được – hoặc nói cách khác, rủi ro s-risks quá kỳ lạ.
Tôi cho rằng đây là lo lắng chính đáng, nhưng tôi không nghĩ chúng ta nên kết luận rằng ngăn chặn rủi ro s-risks là vô ích. Hãy nhớ rằng 10 năm trước, lo ngại về rủi ro từ trí tuệ nhân tạo siêu thông minh gần như bị chế giễu, bác bỏ hoặc hiểu lầm là liên quan đến The Terminator (phim Kẻ huỷ diệt).

Ngược lại, ngày nay chúng ta có Bill Gates viết lời giới thiệu cho một cuốn sách nói về việc mô phỏng toàn bộ não bộ, các thuật toán tối ưu hóa kẹp giấy và tội phạm tâm trí. Tức là, lịch sử của lĩnh vực an toàn trí tuệ nhân tạo cho thấy chúng ta có thể thu hút sự ủng hộ đáng kể cho các lĩnh vực nghiên cứu có vẻ kỳ lạ nếu nỗ lực của chúng ta được hỗ trợ bởi những lập luận vững chắc.
Cuối cùng nhưng không kém phần quan trọng, công việc về rủi ro đau khổ (s-risk) bị bỏ quên đến mức nào?

Rõ ràng nó không hoàn toàn bị bỏ quên. Tôi đã nói trước đó rằng an toàn AI và chính sách AI có thể giảm thiểu rủi ro đau khổ (s-risk), vì vậy có thể nói rằng một số công việc của Viện Nghiên cứu Trí tuệ Máy móc (Machine Intelligence Research Institute - MIRI) hoặc Viện Tương lai của Nhân loại (Future of Humanity Institute - FHI) đang thực sự giải quyết rủi ro đau khổ (s-risk).
Tuy nhiên, theo tôi, rủi ro s-risk nhận được ít sự chú ý hơn so với rủi ro tuyệt chủng (extinction risk). Thực tế, tôi đã thấy rủi ro hiện sinh (existential risk) được đồng nhất với rủi ro tuyệt chủng.
Dù sao đi nữa, tôi cho rằng rủi ro đau khổ (s-risk) nhận được ít sự quan tâm hơn so với mức độ cần thiết. Điều này đặc biệt đúng đối với các can thiệp được thiết kế riêng để giảm thiểu rủi ro đau khổ (s-risk), tức là các can thiệp không đồng thời giảm thiểu các loại rủi ro tồn vong khác. Có thể có những giải pháp dễ dàng ở đây, vì các công việc hiện tại về rủi ro hiện sinh (x-risk) không được tối ưu hóa để giảm thiểu rủi ro đau khổ (s-risk).
Theo như tôi biết, Viện Nghiên cứu Cơ bản (Foundational Research Institute) là tổ chức EA duy nhất tập trung rõ ràng vào việc giảm thiểu rủi ro đau khổ (s-risk).

Tóm lại: cả đánh giá thực nghiệm và đánh giá giá trị đều có liên quan đến việc trả lời câu hỏi liệu có nên tập trung vào việc giảm thiểu rủi ro đau khổ (s-risk) hay không. Về mặt thực nghiệm, những câu hỏi quan trọng nhất là: khả năng xảy ra rủi ro đau khổ (s- risk) là bao nhiêu? Việc ngăn chặn chúng có dễ dàng không? Ai khác đang nghiên cứu về vấn đề này?
Về xác suất của chúng, rủi ro đau khổ (s- risk) có thể không cao, nhưng chúng không chỉ là một khả năng đơn thuần về mặt khái niệm. Chúng ta có thể xác định những công nghệ nào có thể gây ra đau khổ nghiêm trọng trên quy mô vũ trụ, và nhìn chung, đau khổ (s- risk) dường như không ít khả năng xảy ra hơn so với rủi ro tuyệt chủng liên quan đến trí tuệ nhân tạo (AI).
Các công nghệ tiềm năng nhất có thể gây ra rủi ro đau khổ (s- risk) là trí tuệ nhân tạo siêu thông minh (superintelligent AI) và trí tuệ nhân tạo có ý thức (artificial sentience). Do đó, về cơ bản, các lĩnh vực nguyên nhân này có liên quan nhiều hơn đến việc giảm thiểu rủi ro đau khổ (s- risk) so với các lĩnh vực nguyên nhân rủi ro hiện sinh (x-risk) khác như an ninh sinh học hoặc chuyển hướng tiểu hành tinh.
Thứ hai, việc giảm thiểu rủi ro đau khổ (s- risk) ít nhất là có thể thực hiện được. Chúng ta có thể chưa tìm ra các can thiệp hiệu quả nhất trong lĩnh vực này. Nhưng chúng ta có thể chỉ ra một số can thiệp giảm thiểu rủi ro đau khổ (s- risk) mà con người đang nghiên cứu hiện nay, cụ thể là một số công trình hiện tại về an toàn AI và chính sách AI.
Cũng có những biện pháp can thiệp rộng hơn có thể gián tiếp giảm thiểu rủi ro đau khổ (s- risk), nhưng chúng ta vẫn chưa hiểu rõ bức tranh chiến lược tổng thể.
Cuối cùng, rủi ro đau khổ (s- risk) dường như bị bỏ qua nhiều hơn so với rủi ro tuyệt chủng (extinction risk). Đồng thời, việc giảm thiểu rủi ro rủi ro đau khổ (s- risk) là khó khăn và đòi hỏi những nỗ lực tiên phong. Vì vậy, tôi cho rằng FRI chiếm một vị trí quan trọng với nhiều không gian cho những người khác tham gia.
Dù vậy, tôi không mong đợi sẽ thuyết phục được tất cả các bạn tập trung vào việc giảm thiểu rủi ro đau khổ (s- risk). Tôi nghĩ rằng, thực tế, chúng ta sẽ có sự đa dạng về ưu tiên trong cộng đồng, với một số người tập trung vào việc giảm thiểu rủi ro tuyệt chủng, một số người tập trung vào việc giảm thiểu rủi ro rủi ro đau khổ (s- risk), và v.v.
Do đó, tôi muốn kết thúc bài phát biểu này với một tầm nhìn về cộng đồng có định hình tương lai xa.

Những người trong chúng ta quan tâm đến tương lai xa xôi đang đối mặt với một hành trình dài. Nhưng việc mô tả điều này như một sự lựa chọn nhị nguyên giữa sự tuyệt chủng và thiên đường là một sự hiểu lầm.

Nhưng theo một nghĩa khác, ẩn dụ đó rất phù hợp. Chúng ta thực sự đang đối mặt với một hành trình dài, nhưng đó là một hành trình qua vùng đất khó khăn, và trên đường chân trời là một dải liên tục từ cơn bão kinh hoàng đến ngày hè đẹp nhất. Sự quan tâm đến việc định hình tương lai xa xôi quyết định ai sẽ ở trong xe, nhưng không quyết định chính xác phải làm gì với vô lăng. Một số người lo lắng nhất về việc tránh cơn bão, trong khi những người khác lại được thúc đẩy bởi hy vọng tồn tại về việc đạt được ngày hè. Chúng ta không thể theo dõi mạng lưới đường xá phức tạp ở phía trước, nhưng chúng ta dễ dàng nhìn thấy ai khác đang ở trong xe và có thể trò chuyện với họ – vậy có lẽ điều hiệu quả nhất chúng ta có thể làm bây giờ là so sánh bản đồ của mình về vùng đất đó, và thống nhất về cách xử lý những bất đồng còn lại mà không làm xe trật đường.

Cảm ơn.
Để biết thêm thông tin về s-risk, vui lòng truy cập foundational-research.org. Nếu bạn có bất kỳ câu hỏi nào, vui lòng gửi email cho tôi tại max@foundational-research.org hoặc liên hệ qua Facebook.
Nếu bạn quan tâm đến việc tìm hiểu cách làm nhiều điều tốt hơn, đây là một số bước tiếp theo bạn có thể thực hiện.
Khám phá các ý tưởng và hành động thực tiễn để tạo ra tác động tích cực.
Địa điểm: Trường Đại học Kinh tế - Tài chính Thành phố Hồ Chí Minh, Cơ sở chính 141 - 145 Điện Biên Phủ, Phường Gia Định, Thành phố Hồ Chí Minh.
Thời gian: 9:00 - 17:00 ngày 11/07/2026

